
Data Fabric is often translated in a wrong way, something like “information factory.” This is wrong. The resource has nothing to do with industry or factories. It is a data fabric that includes an information management infrastructure with flexible and comprehensive access to information.
System description
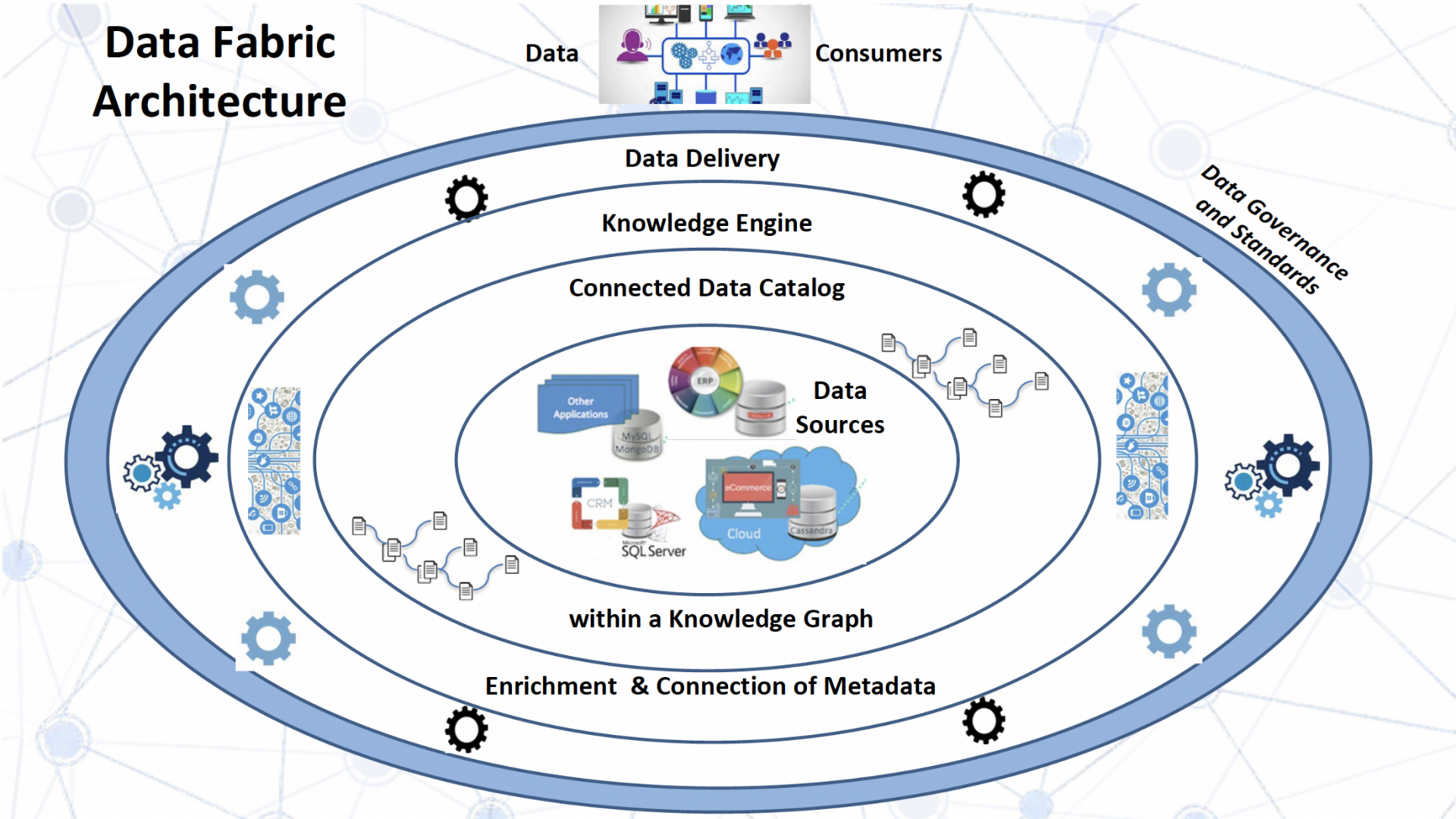
Data Fabric is a self-contained system used for extremely efficient user access to corporate information. With the help of this program, it is easier to find and process data in accordance with the rules of other information systems.
Algorithm of actions to use Data Fabric:
- MDM Installation.
- Loading Data Catalog.
- Meta-data setup.
- Implementation of data quality management with subsequent monitoring and development of regulations.
- Systematization of tools for adding and updating information.
- Data virtualization and data efficiency analysis.
- Activation of Data Governance approaches.
The algorithm above is rarely followed precisely step by step. Activities with regular improvements in the enterprise or organization bring the necessary results.
The implementation of innovative technologies and improvement of existing tools is welcome. The Data Fabric team concept is designed for continuous maturity and implementation of innovative technologies.
What is the distinction between Data Fabric and Data Lake?
Here the division is quite clear. Data Lake is the concept of centralization of information. Data Fabric is the distribution of work with available and incoming data. These options are not mutually exclusive. They complement each other to perform certain tasks.
For example, DL is implemented for specific sources. DF is more suited for business development. Both programs can safely exist in the same company or organization. The Data Mesh system should be noted separately. The key differences from the above-mentioned systems are:
- this application is not intended to visualize the data provided;
- entrance in Data as a product;
- self-serve data infrastructure as a platform service set is performed;
- operation confirmation is performed in Federated computational governance.
Integral components
The Data Fabric system consists of a number of components. Among them, the following:
- Information processing with machine learning.
- Obtaining data with optimization of existing steps followed by analysis.
- Consumers all over the world are connected by seamless integration using Data Lake-type repositories and databases via APIs.
- Use of microservice architectures.
- Availability of cloud solutions with an emphasis on virtualization of IT structures.
- Security and easy access to the service.
Data Fabric operates on the Data Ops concept. It reacts quickly to any possible changes in the information and increases the level of predictions and optimizing the storage, usage, and processing of the resources.
Characteristics
A distinctive feature of Data Fabric is the intensive introduction of innovative technologies using artificial intelligence and the practical use of machine programs to build and, if necessary, fix working algorithms. Another feature is the filling of semantic graphs that define and standardize all the data practiced in the business terms adapted to the end user.
In simple terms, the Data Fabric is a user-level organization system in which everything is subordinate to the information collected and the conclusions drawn from it. Experts classify the program as technological and organizational modern technology.